
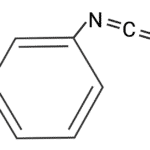
Phản ứng phân hủy Edman
10/03/2025
Glycosyl hóa: Biến đổi sau dịch mã và tác động lên cấu trúc chức năng protein
11/03/2025
Cách mạng hóa Proteomics: Tiến bộ trong công nghệ, tích hợp AI và ứng dụng rộng hơn
Cách mạng hóa Proteomics: Tiến bộ trong công nghệ, tích hợp AI và ứng dụng rộng hơn
1. Sự phát triển của công nghệ Proteomics
1.1 Proteomics dựa trên khối phổ
Proteomics dựa trên khối phổ là một lĩnh vực năng động và then chốt trong lĩnh vực khoa học sự sống, sử dụng một loạt các kỹ thuật phân tích đa dạng được phân loại thành các phương pháp thông lượng thấp và cao. Công nghệ Proteomics đã trải qua nhiều mốc thời gian quan trọng trong quá trình phát triển (Hình 1). Những năm 1970, sự ra đời của kỹ thuật điện di hai chiều (2D electrophoresis) cho phép phân tách các protein dựa trên điểm đẳng điện (pI) và khối lượng phân tử, đánh dấu bước đầu tiên trong việc phân tích quy mô lớn các protein. Những năm 1980, phát triển kỹ thuật khối phổ (Mass Spectrometry – MS) để phân tích protein. Đây là công cụ mạnh mẽ giúp xác định và định lượng protein với độ chính xác cao. Những năm 1990 – 2000, sự phát triển của các kỹ thuật khối phổ MALDI-TOF (Matrix-Assisted Laser Desorption/Ionization Time-of-Flight) và ESI (Electrospray Ionization) giúp cải thiện đáng kể khả năng phân tích protein. Năm 2001, hoàn thành dự án giải mã bộ gen người (Human Genome Project) tạo tiền đề cho việc nghiên cứu sâu hơn về protein và chức năng của chúng trong cơ thể người. Những năm 2000 – 2010, sự phát triển của các phương pháp định lượng protein như iTRAQ (Isobaric Tags for Relative and Absolute Quantitation) và SILAC (Stable Isotope Labeling by Amino acids in Cell culture) giúp nghiên cứu sự biểu hiện protein trong các điều kiện khác nhau. Những năm 2010 – nay, sự phát triển của các công nghệ như single-cell proteomics và spatial proteomics cho phép nghiên cứu protein ở mức độ tế bào đơn và trong không gian ba chiều của mô, mở ra những hướng nghiên cứu mới trong y học và sinh học. Người đi đầu trong cuộc cách mạng này là Giáo sư Matthias Mann, một nhà khoa học nổi tiếng toàn cầu, hiện đang giữ chức giám đốc nghiên cứu của Chương trình Proteomics tại Trung tâm Nghiên cứu Protein của Quỹ Novo Nordisk và giám đốc Viện Hóa sinh Max Planck tại Munich. Mann xác định một bước đột phá đặc biệt trong lĩnh vực proteomics của MS do phòng thí nghiệm Aebersold dẫn đầu—quá trình chuyển đổi sang thu thập dữ liệu DIA.
DIA (Data-Independent Acquisition), còn được gọi là Sequential Window Acquisition of All Theoretical Mass Spectra (SWATH-MS), là một phương pháp tiên tiến trong phân tích khối phổ (MS) so với phương pháp truyền thống Data-Dependent Analysis (DDA). Khác với DDA, DIA không chọn lọc các ion tiền chất dựa trên cường độ tín hiệu mà phân tích toàn bộ các ion tiền chất trong cả hai chu kỳ MS1 và MS2. Điều này giúp loại bỏ sự thiên vị trong việc lựa chọn ion, mang lại dữ liệu toàn diện hơn. DIA cung cấp phân tích không thiên vị, phạm vi proteome rộng hơn và khả năng lặp lại được tăng lên. Ví dụ cụ thể về ứng dụng của DIA trong nghiên cứu proteomic:
- Ung thư học: Năm 2019, có 42 nghiên cứu sử dụng DIA-MS để phân tích proteomic trong các loại ung thư khác nhau. Phương pháp này giúp xác định các dấu ấn sinh học liên quan đến ung thư, hỗ trợ chẩn đoán và điều trị bệnh.
- Khoa học thần kinh: DIA đã góp phần khám phá thông tin mới về các bệnh thần kinh như Alzheimer, cung cấp cái nhìn sâu sắc về cơ chế bệnh lý và tiềm năng điều trị.
- Nghiên cứu COVID-19: Gần đây, DIA-MS đã được sử dụng trong nghiên cứu protein “siêu nhanh”, giúp xác định và xác nhận 43 dấu ấn sinh học protein huyết tương mới, trong đó có 11 dấu ấn liên quan đến mức độ nghiêm trọng của COVID-19.
Theo Johnston, DIA-MS đóng vai trò quan trọng trong việc chuẩn hóa quy trình làm việc trong nghiên cứu proteomic. Phương pháp này giúp giảm thiểu sự khác biệt trong kết quả giữa các phòng thí nghiệm, tạo ra một bối cảnh nghiên cứu nhất quán và đáng tin cậy hơn. Điều này đặc biệt quan trọng trong lĩnh vực proteomic dựa trên khối phổ, nơi mà sự chính xác và độ tin cậy của dữ liệu là yếu tố then chốt.
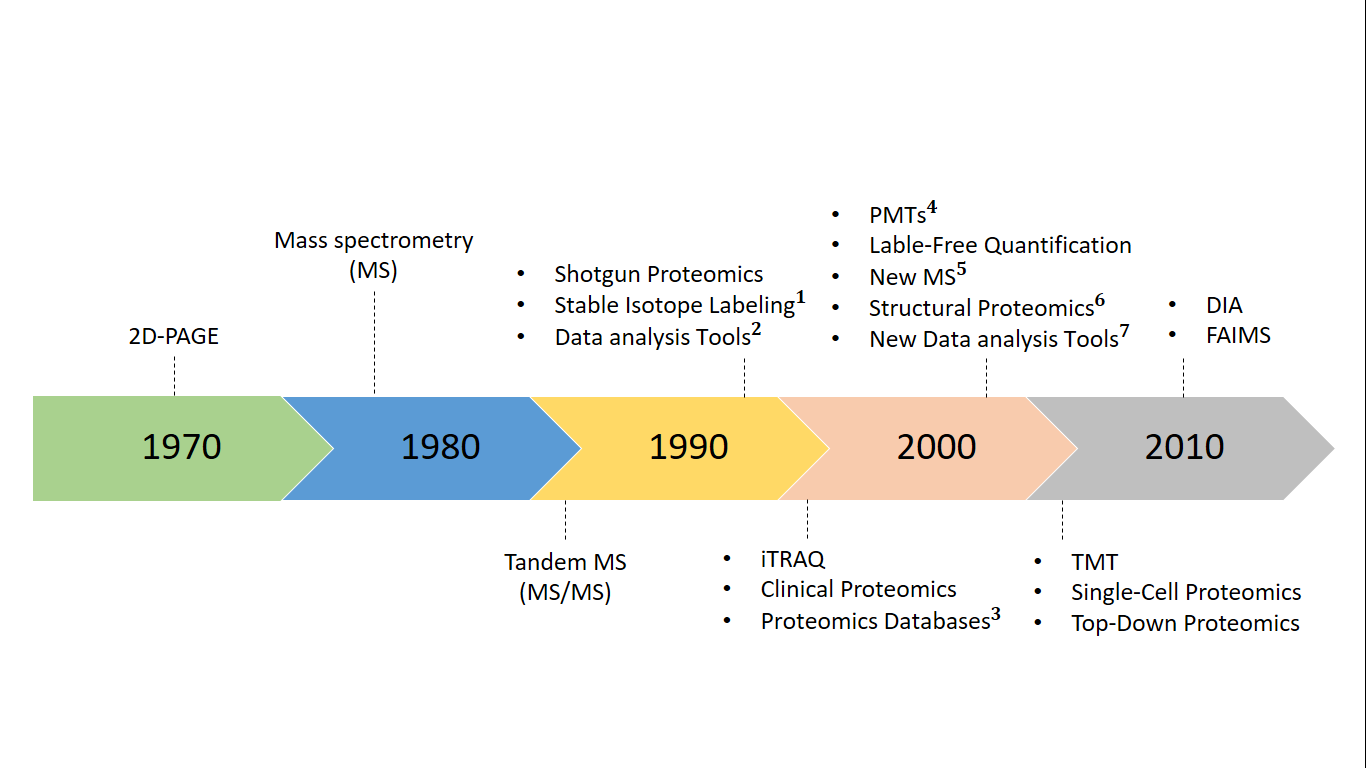
Hình 1. Dòng thời gian của các sự kiện chính liên quan đến nghiên cứu về proteomic. Các đường thẳng nét đứt chỉ ra các sự kiện sớm, giữa hoặc muộn tùy thuộc vào vị trí của chúng. Ví dụ về một số sự kiện: (1) stable isotope labeling by amino acids (SILAC), Isotope-coded Affinity Tag (ICAT); (2) SEQUEST, Mascot, and Scaffold; (3) UniProt, National Institutes of Health database; (4) Phosphoproteome, Acetylome, Ubiqutinome, etc.; (5) Orbitrap, Q-TOF; (6) Hydrogen Deuterium Exchange (HDX)-MS; (7) Skyline, MaxQuant. iTRAQ: Isobaric Tags for Relative and Absolute Quantitation. TMT: Tandem Mass Tags. FAIMS: Field Asymmetric Ion Mobility Spectrometry. DIA: Data-independent acquisition.
1.2 Những tiến bộ trong Proteomics dựa trên Aptamer
Trong bối cảnh phát triển không ngừng của lĩnh vực proteomics, sự xuất hiện của các nền tảng proteomics “thế hệ thứ hai” dựa trên công nghệ aptamer đang tạo ra một sự thay đổi mô hình đáng kể so với các phương pháp truyền thống dựa trên kháng thể. Trong khi phổ khối (MS) từ lâu đã là công cụ chủ đạo trong nghiên cứu proteomics, các phương pháp dựa trên aptamer đang mở ra những hướng tiếp cận mới, đặc biệt trong việc khám phá proteome với độ chính xác và tính chọn lọc cao hơn.
Ưu điểm của Aptamer so với Kháng thể: Aptamer là các phân tử DNA hoặc RNA mạch đơn ngắn, có khả năng tạo ra các cấu hình không gian đặc biệt, cho phép chúng liên kết chọn lọc với các mục tiêu sinh học cụ thể, đặc biệt là protein. So với kháng thể, aptamer mang lại nhiều lợi thế:
- Tính đặc hiệu cao: Aptamer có thể được thiết kế để nhận biết và liên kết với các mục tiêu cụ thể một cách chính xác, ngay cả trong các môi trường phức tạp.
- Tính linh hoạt: Chúng có thể được tổng hợp hóa học với chi phí thấp và dễ dàng điều chỉnh để cải thiện hiệu suất.
- Ổn định hơn: Aptamer ít bị ảnh hưởng bởi các điều kiện môi trường như nhiệt độ và pH so với kháng thể.
- Phạm vi động rộng: Công nghệ aptamer có khả năng phát hiện các protein có hàm lượng thấp, điều mà MS truyền thống thường gặp khó khăn.
Ứng dụng trong Nghiên cứu Y sinh: các phương pháp dựa trên aptamer đã chứng minh tiềm năng to lớn trong việc khám phá các dấu ấn sinh học và hiểu biết sâu hơn về các quá trình bệnh lý. Ví dụ: Bệnh gan nhiễm mỡ không do rượu (NAFLD): Công nghệ aptamer đã giúp xác định các protein liên quan đến xơ hóa gan, mở ra hướng nghiên cứu mới trong chẩn đoán và điều trị. Đối với bệnh tim mạch, proteomics dựa trên aptamer đã đóng góp vào việc phát hiện các dấu ấn sinh học liên quan đến tái tạo tim và suy tim, cung cấp thông tin quan trọng cho các liệu pháp điều trị.
So sánh với Phổ khối (MS): Mặc dù MS vẫn là công cụ mạnh mẽ để phân tích toàn diện proteome, nó có một số hạn chế, đặc biệt là trong việc phát hiện các protein có hàm lượng thấp. Công nghệ aptamer bổ sung cho MS bằng cách cung cấp một phương pháp tiếp cận có mục tiêu và chọn lọc hơn, đặc biệt hữu ích trong việc nghiên cứu các tương tác protein và động lực học tế bào.
Tương lai của Proteomics dựa trên Aptamer: Tiến sĩ Benjamin Orsburn từ Đại học Johns Hopkins nhấn mạnh rằng, sự xuất hiện của công nghệ aptamer đang thay đổi cách tiếp cận truyền thống trong nghiên cứu protein. Trong tương lai, sự kết hợp giữa MS và công nghệ aptamer có thể mang lại những hiểu biết sâu sắc hơn về proteome, đặc biệt trong các lĩnh vực như khám phá dấu ấn sinh học và nghiên cứu bệnh lý.
2. Trí tuệ nhân tạo cách mạng hóa nghiên cứu protein
2.1. AI trong khám phá thuốc và tương tác protein
Theo Tiến sĩ Octavian-Eugen Ganea từ Phòng thí nghiệm khoa học máy tính và trí tuệ nhân tạo (CSAIL) của MIT, việc khám phá thủ công các tương tác protein mà không có sự hỗ trợ của AI sẽ là một quá trình cực kỳ tốn thời gian. AI đang cách mạng hóa lĩnh vực khám phá thuốc và nghiên cứu tương tác protein, không chỉ giúp tăng tốc quá trình nghiên cứu mà còn mở ra cánh cửa cho các liệu pháp điều trị mới và hiệu quả hơn.
AI trong Khám Phá Thuốc có những đặc điểm: thứ nhất là xử lý lượng dữ liệu khổng lồ từ các thí nghiệm, nghiên cứu lâm sàng và cơ sở dữ liệu khoa học để tìm ra các mẫu và xu hướng tiềm năng; thứ hai là giúp xác định các protein hoặc gen có thể là mục tiêu cho thuốc mới, dựa trên dữ liệu di truyền và sinh học phân tử; thứ ba là thiết kế các phân tử thuốc mới bằng cách dự đoán cấu trúc phân tử và tương tác với đích tác động; thứ tư là tối ưu hóa các phân tử thuốc để cải thiện hiệu quả và giảm tác dụng phụ; và thứ năm dự đoán độc tính và các phản ứng phụ tiềm ẩn của thuốc trước khi thử nghiệm lâm sàng.
AI trong Tương Tác Protein có những có những đặc điểm: thứ nhất là các mô hình học sâu như AlphaFold, có thể dự đoán cấu trúc 3D của protein từ trình tự amino acid; thứ hai là phân tích và dự đoán các tương tác giữa các protein, điều này rất quan trọng trong việc hiểu các quá trình sinh học và bệnh lý; thứ ba là tối ưu hóa các tương tác protein để phát triển các liệu pháp điều trị mới, chẳng hạn như các kháng thể đơn dòng; thứ tư là phát hiện các đột biến trong protein có thể ảnh hưởng đến chức năng và tương tác của chúng, từ đó giúp hiểu rõ hơn về các bệnh di truyền; và thứ năm là mô phỏng động lực học phân tử của protein, giúp hiểu rõ hơn về cách chúng hoạt động và tương tác trong cơ thể.
2.2. EquiDock: Một bước đột phá trong việc gắn kết protein
EquiDock là một phương pháp tính toán tiên tiến, sử dụng trí tuệ nhân tạo (AI) và học sâu (deep learning) để dự đoán cách các protein gắn kết với nhau. Mô hình EquiDock, do nhóm Ganea tại MIT phát triển. Điểm nổi bật của EquiDock là khả năng sử dụng trực tiếp cấu trúc 3D của hai protein để xác định các vùng có khả năng tương tác, thay vì dựa vào các thông tin gián tiếp như trình tự amino acid hay các đặc điểm hóa học. Với khả năng nắm bắt các mẫu ghép phức tạp từ khoảng 41.000 cấu trúc protein, mô hình ràng buộc hình học của EquiDock là một phương pháp tiên tiến trong lĩnh vực dự đoán tương tác protein-protein. Dưới đây là một số đặc điểm chính về mô hình này:
- Ràng buộc hình học: EquiDock sử dụng các ràng buộc hình học để mô hình hóa cách các protein tương tác với nhau. Điều này giúp mô hình có thể dự đoán chính xác cấu trúc phức hợp protein mà không cần dựa vào thông tin tiên nghiệm về vị trí liên kết.
- Hàng nghìn tham số điều chỉnh động: Mô hình này có khả năng điều chỉnh hàng nghìn tham số trong quá trình tính toán, giúp tối ưu hóa quá trình dự đoán và cải thiện độ chính xác.
- Tốc độ vượt trội: EquiDock có thể dự đoán các phức hợp protein trong vòng một đến năm giây, nhanh hơn từ 80 đến 500 lần so với các phần mềm hiện có. Điều này làm cho nó trở thành công cụ mạnh mẽ cho các nghiên cứu y sinh và dược phẩm, nơi mà tốc độ và độ chính xác là yếu tố then chốt.
- Ứng dụng thực tiễn: Với tốc độ và độ chính xác cao, EquiDock có tiềm năng lớn trong việc phát triển các loại thuốc mới, nghiên cứu các tương tác protein trong bệnh lý, và nhiều ứng dụng khác trong sinh học phân tử và y học.
2.3. AI trong phổ khối và hơn thế nữa
AI đang hỗ trợ các nhà nghiên cứu trong việc trích xuất nhiều thông tin chi tiết hơn từ dữ liệu thu được thông qua các thí nghiệm khối phổ, một quá trình được biết đến với bản chất tốn thời gian và khả năng xảy ra lỗi trong việc xác định protein. Các phương pháp học sâu, chẳng hạn như Prosit, DeepMass và DeepDIA, đã được phát triển để dự đoán các đặc điểm của quang phổ và peptide. Điều này được kỳ vọng sẽ tối ưu hóa các phương pháp thu thập dữ liệu độc lập (DIA), định hướng lĩnh vực nghiên cứu về protein theo hướng hiệu quả và chính xác hơn.
2.4. AI trong Proteomics phi khối phổ và DeepFRET
2.4.1. AI trong Proteomics phi khối phổ
Các phương pháp phi khối phổ (non-mass spectrometry) trong proteomics thường sử dụng các kỹ thuật như điện di gel, microarray protein, và kính hiển vi huỳnh quang. Ứng dụng của AI:
- Phân tích hình ảnh: AI có thể phân tích hình ảnh từ điện di gel hoặc kính hiển vi huỳnh quang để xác định vị trí và lượng protein.
- Dự đoán tương tác protein: Các mô hình học máy có thể dự đoán tương tác giữa các protein dựa trên dữ liệu cấu trúc và trình tự.
- Phân loại protein: AI có thể phân loại protein dựa trên các đặc điểm hình ảnh hoặc dữ liệu sinh học khác.
2.4.2. DeepFRET
DeepFRET là một phương pháp sử dụng kỹ thuật FRET (Förster Resonance Energy Transfer) kết hợp với học sâu (deep learning) để nghiên cứu tương tác và động học của protein ở mức độ phân tử.
FRET: Là kỹ thuật đo lường sự chuyển năng lượng giữa hai phân tử huỳnh quang gần nhau, thường được sử dụng để nghiên cứu tương tác protein-protein.
Deep Learning trong DeepFRET:
-
- Phân tích dữ liệu FRET: Các mô hình học sâu có thể phân tích dữ liệu FRET phức tạp để xác định khoảng cách và động học giữa các protein.
- Tự động hóa: AI có thể tự động hóa quá trình phân tích dữ liệu FRET, giảm thiểu sai sót và tăng tốc độ nghiên cứu.
- Dự đoán tương tác: Các mô hình học sâu có thể dự đoán tương tác và động học của protein dựa trên dữ liệu FRET.
2.4.3. Kết hợp AI và DeepFRET trong Proteomics
Các phương pháp liên quan đến kính hiển vi và truyền năng lượng cộng hưởng Förster (FRET) tốn nhiều thời gian và đòi hỏi chuyên môn đáng kể để phân tích các tập dữ liệu lớn. Để giải quyết thách thức này, các nhà nghiên cứu do Giáo sư Nikos Hatzakis đứng đầu đã tạo ra mô hình DeepFRET—một thuật toán học máy tự động hóa việc nhận dạng các mẫu chuyển động của protein.
- Nâng cao độ chính xác: AI có thể cải thiện độ chính xác của các phép đo FRET, giúp nghiên cứu tương tác protein chi tiết hơn.
- Tăng tốc độ nghiên cứu: Tự động hóa quá trình phân tích dữ liệu giúp tăng tốc độ nghiên cứu và giảm thời gian cần thiết để đưa ra kết luận.
- Khám phá mới: AI có thể giúp khám phá các tương tác protein mới và hiểu rõ hơn về cơ chế hoạt động của chúng.
AI và DeepFRET đang mở ra những hướng nghiên cứu mới trong proteomics, giúp các nhà khoa học hiểu rõ hơn về cấu trúc và chức năng của protein, cũng như tương tác giữa chúng trong các hệ thống sinh học phức tạp.
3. Các ứng dụng rộng hơn của Proteomics
Proteomics, nghiên cứu về toàn bộ protein trong một hệ thống sinh học, có nhiều ứng dụng rộng rãi trong các lĩnh vực khác nhau. Dưới đây là một số ứng dụng chính của proteomics:
Y học và Sức khỏe
- Chẩn đoán bệnh: Proteomics giúp xác định các dấu ấn sinh học (biomarkers) liên quan đến các bệnh như ung thư, bệnh tim mạch, và các bệnh thoái hóa thần kinh.
- Phát triển thuốc: Nghiên cứu protein giúp hiểu rõ hơn về cơ chế bệnh và phát triển các loại thuốc mới, đặc biệt là trong lĩnh vực điều trị ung thư.
- Y học cá nhân hóa: Proteomics cho phép phân tích các protein cụ thể của từng cá nhân, giúp tối ưu hóa phác đồ điều trị dựa trên đặc điểm sinh học riêng biệt.
Nông nghiệp
- Cải thiện giống cây trồng: Proteomics giúp hiểu rõ hơn về các protein liên quan đến sự phát triển, chống chịu stress, và năng suất của cây trồng.
- Bảo vệ thực vật: Nghiên cứu protein giúp phát hiện và kiểm soát các bệnh thực vật, cải thiện khả năng chống chịu của cây trồng với các điều kiện bất lợi.
Công nghiệp thực phẩm
- An toàn thực phẩm: Proteomics được sử dụng để phát hiện các chất gây dị ứng, độc tố, và vi sinh vật gây bệnh trong thực phẩm.
- Cải thiện chất lượng thực phẩm: Nghiên cứu protein giúp tối ưu hóa quy trình sản xuất và bảo quản thực phẩm, cải thiện hương vị và giá trị dinh dưỡng.
Môi trường
- Giám sát môi trường: Proteomics có thể được sử dụng để đánh giá tác động của các chất ô nhiễm lên hệ sinh thái và sức khỏe con người.
- Xử lý ô nhiễm: Nghiên cứu protein giúp phát triển các phương pháp sinh học để xử lý chất thải và ô nhiễm môi trường.
Công nghệ sinh học
- Kỹ thuật protein: Proteomics hỗ trợ trong việc thiết kế và cải tiến các protein có chức năng đặc biệt, như enzyme công nghiệp và protein trị liệu.
- Hệ thống sinh học tổng hợp: Proteomics đóng vai trò quan trọng trong việc thiết kế và tối ưu hóa các hệ thống sinh học tổng hợp.
Nghiên cứu cơ bản
- Hiểu biết về sinh học phân tử: Proteomics cung cấp cái nhìn toàn diện về các quá trình sinh học ở mức độ phân tử, giúp hiểu rõ hơn về cơ chế hoạt động của tế bào và sinh vật.
- Tương tác protein: Nghiên cứu các mạng lưới tương tác protein giúp hiểu rõ hơn về các con đường tín hiệu và điều hòa trong tế bào.
Pháp y
- Nhận dạng sinh học: Proteomics có thể được sử dụng để xác định các mẫu sinh học trong các vụ án hình sự.
- Phân tích dấu vết sinh học: Proteomics giúp phân tích các dấu vết protein để xác định nguyên nhân tử vong hoặc các yếu tố liên quan đến tội phạm.
Dược phẩm và Mỹ phẩm
- Phát triển sản phẩm: Proteomics giúp nghiên cứu và phát triển các sản phẩm dược phẩm và mỹ phẩm dựa trên cơ chế tác động của protein.
- Đánh giá hiệu quả và an toàn: Proteomics được sử dụng để đánh giá hiệu quả và độ an toàn của các sản phẩm mới.
4. Những thách thức và triển vọng tương lai của Proteomics
Proteomics, nghiên cứu quy mô lớn về protein, đã có những bước tiến đáng kể trong những thập kỷ gần đây. Tuy nhiên, lĩnh vực này vẫn đối mặt với nhiều thách thức, đồng thời mở ra nhiều triển vọng hấp dẫn trong tương lai. Dưới đây là một số thách thức và triển vọng chính:
4.1. Thách thức
- Độ phức tạp: Proteome (tập hợp tất cả protein trong một tế bào hoặc mô) có độ phức tạp cao do sự đa dạng của protein về cấu trúc, chức năng và biến đổi sau dịch mã (post-translational modifications – PTMs). Điều này làm cho việc phân tích toàn diện trở nên khó khăn.
- Độ nhạy và độ phân giải của công nghệ: Mặc dù các công nghệ như khối phổ (mass spectrometry) đã được cải thiện đáng kể, việc phát hiện và định lượng các protein có nồng độ thấp vẫn là một thách thức lớn.
- Xử lý và phân tích dữ liệu: Proteomics tạo ra lượng dữ liệu khổng lồ, đòi hỏi các công cụ tin sinh học mạnh mẽ và các phương pháp phân tích tiên tiến để xử lý và diễn giải dữ liệu một cách chính xác.
- Sự biến đổi sinh học: Proteome có thể thay đổi tùy thuộc vào điều kiện sinh lý, bệnh lý và môi trường, làm tăng tính phức tạp của việc nghiên cứu và so sánh giữa các mẫu khác nhau.
- Chi phí và thời gian: Các phương pháp proteomics hiện đại thường đòi hỏi chi phí cao và thời gian dài, hạn chế khả năng ứng dụng rộng rãi trong nghiên cứu và lâm sàng.
- Giới hạn của thiết bị đo lường: Tiến trình của proteomics có liên quan chặt chẽ với những tiến bộ trong thiết bị đo lường. Tuy nhiên, các công nghệ hiện tại phải đối mặt với những hạn chế về độ nhạy, độ phân giải và phạm vi động. Việc giải quyết những hạn chế này là rất quan trọng để mở khóa toàn bộ tiềm năng của phân tích proteomics.
- Sự thay đổi trong quá trình chuẩn bị mẫu: Sự thay đổi trong các kỹ thuật chuẩn bị mẫu giữa các phòng thí nghiệm có thể gây ra sai lệch và cản trở khả năng tái tạo kết quả. Việc chuẩn hóa các giao thức và thiết lập các biện pháp kiểm soát chất lượng là điều cần thiết để giảm thiểu thách thức này.
4.2. Triển vọng tương lai
- Cải tiến công nghệ: Sự phát triển của các công nghệ mới như khối phổ độ phân giải cao, microfluidics, và các phương pháp phân tích đơn bào (single-cell proteomics) sẽ giúp tăng độ nhạy, độ phân giải và tốc độ phân tích. Những cải tiến về độ nhạy, tốc độ và khả năng mô tả các sửa đổi sau dịch mã sẽ mở rộng phạm vi phân tích proteomic.
- Ứng dụng trong y học cá thể hóa: Proteomics có tiềm năng lớn trong việc phát triển các phương pháp chẩn đoán, điều trị và theo dõi bệnh tật một cách cá thể hóa, dựa trên đặc điểm proteome của từng bệnh nhân.
- Khám phá dấu ấn sinh học (biomarkers): Proteomics có thể giúp phát hiện các dấu ấn sinh học mới cho các bệnh như ung thư, bệnh tim mạch và bệnh thần kinh, từ đó cải thiện chẩn đoán sớm và điều trị.
- Nghiên cứu tương tác protein và mạng lưới tín hiệu: Hiểu biết sâu hơn về các tương tác protein và mạng lưới tín hiệu trong tế bào sẽ giúp làm sáng tỏ các cơ chế phân tử của bệnh tật và phát triển các liệu pháp điều trị mới.
- Tích hợp đa omics: Sự tích hợp của proteomics với các lĩnh vực omics khác như genomics, transcriptomics và metabolomics sẽ cung cấp một cái nhìn toàn diện hơn về sinh học hệ thống và các quá trình bệnh lý.
- Phát triển thuốc và liệu pháp mới: Proteomics có thể đóng vai trò quan trọng trong việc phát hiện các mục tiêu thuốc mới và đánh giá hiệu quả của các liệu pháp điều trị.
- Ứng dụng trong nông nghiệp và công nghiệp: Proteomics cũng có tiềm năng ứng dụng trong nông nghiệp để cải thiện năng suất cây trồng và trong công nghiệp để phát triển các sản phẩm sinh học mới.
- Sự hội tụ công nghệ: Sự hội tụ của các công nghệ như trí tuệ nhân tạo và máy học sẽ cách mạng hóa việc giải thích dữ liệu và đẩy nhanh việc xác định các mô hình sinh học có ý nghĩa. Các thuật toán thông minh sẽ nâng cao hiệu quả của các phân tích proteomic, giúp các nghiên cứu quy mô lớn khả thi hơn.
- Chuẩn hóa và cộng tác: Việc thiết lập các giao thức chuẩn hóa và thúc đẩy sự hợp tác giữa các cộng đồng nghiên cứu là tối quan trọng. Các nguồn lực và kho dữ liệu được chia sẻ sẽ tạo điều kiện thuận lợi cho việc xác thực chéo các phát hiện, đảm bảo tính mạnh mẽ và khả năng tái tạo của các nghiên cứu về protein.
Tóm lại, proteomics đang đứng trước nhiều thách thức kỹ thuật và sinh học, nhưng với sự phát triển không ngừng của công nghệ và phương pháp nghiên cứu, lĩnh vực này hứa hẹn sẽ mang lại những đột phá lớn trong y học, sinh học và các ngành công nghiệp khác. Sự kết hợp giữa các phương pháp tiếp cận đa omics và ứng dụng trí tuệ nhân tạo sẽ mở ra những hướng đi mới, giúp khám phá sâu hơn về thế giới protein và vai trò của chúng trong sự sống.
Bài viết mới >>
- Các phương pháp phân tích định lượng, định tính
 Các phương pháp phân tích định lượng, định tính Giá trên đã bao gồm thuế phí.
Các phương pháp phân tích định lượng, định tính Giá trên đã bao gồm thuế phí. - Các phương pháp phân tích Sinh Hóa Lý
- Tổng quan về ELISA
 ELISA (Enzyme-linked immunosorbent assay) là kỹ thuật xét nghiệm miễn dịch sử dụng enzyme để phát hiện và định lượng kháng nguyên hoặc kháng thể. Có […]
ELISA (Enzyme-linked immunosorbent assay) là kỹ thuật xét nghiệm miễn dịch sử dụng enzyme để phát hiện và định lượng kháng nguyên hoặc kháng thể. Có […] - Các phương pháp chiết tách protein trong nghiên cứu proteomics và ứng dụng
 Các tiến bộ trong công nghệ proteomics không thể khắc phục được các vấn đề trong chuẩn bị mẫu. Các bước như đồng nhất hóa mô, […]
Các tiến bộ trong công nghệ proteomics không thể khắc phục được các vấn đề trong chuẩn bị mẫu. Các bước như đồng nhất hóa mô, […] - Sự hình thành cầu disulfide trong protein
 Tầm quan trọng của cầu nối Disulfide Ổn định cấu trúc Protein: Cầu nối disulfide giúp ổn định cấu trúc bậc ba và bậc bốn của […]
Tầm quan trọng của cầu nối Disulfide Ổn định cấu trúc Protein: Cầu nối disulfide giúp ổn định cấu trúc bậc ba và bậc bốn của […] - TỔNG QUAN WESTERN BLOTTING
 Western Blotting (WB) là kĩ thuật phân tích protein được sử dụng rộng rãi trong ngành sinh hoá, sinh học phân tử. Là một kĩ thuật […]
Western Blotting (WB) là kĩ thuật phân tích protein được sử dụng rộng rãi trong ngành sinh hoá, sinh học phân tử. Là một kĩ thuật […] - Palmitoyl và khử palmitoyl: Vai trò trong sinh học tế bào và ung thư
 Palmitoyl hóa là quá trình gắn nhóm palmitate vào protein, giúp điều chỉnh vị trí và chức năng của chúng. Quá trình này có thể đảo […]
Palmitoyl hóa là quá trình gắn nhóm palmitate vào protein, giúp điều chỉnh vị trí và chức năng của chúng. Quá trình này có thể đảo […] - Phân tích trình tự kháng thể: Khám phá sự đa dạng và ứng dụng
 Cấu trúc kháng thể Kháng thể, còn được gọi là immunoglobulin, là một cấu trúc hình chữ Y bao gồm bốn chuỗi polypeptide – hai chuỗi […]
Cấu trúc kháng thể Kháng thể, còn được gọi là immunoglobulin, là một cấu trúc hình chữ Y bao gồm bốn chuỗi polypeptide – hai chuỗi […] - Giải trình tự peptide: Công cụ cốt lõi trong nghiên cứu Proteomics
 Giải trình tự peptide là quá trình xác định trình tự các axit amin trong một chuỗi peptide. Đây là kỹ thuật then chốt trong proteomics, […]
Giải trình tự peptide là quá trình xác định trình tự các axit amin trong một chuỗi peptide. Đây là kỹ thuật then chốt trong proteomics, […] - Phân tích axit amin trong dinh dưỡng và công nghiệp thực phẩm
 Axit amin đóng vai trò then chốt trong việc làm sáng tỏ mối quan hệ phức tạp giữa dinh dưỡng và ngành công nghiệp thực phẩm. […]
Axit amin đóng vai trò then chốt trong việc làm sáng tỏ mối quan hệ phức tạp giữa dinh dưỡng và ngành công nghiệp thực phẩm. […]


